

This post continues my thoughts on AI as the opposite of education: you can check back there for a list of them all as they come together.
(Not so much) innovation
While the benefits of AI in learning and teaching continue to be debated, its transformational impact on research and innovation is widely accepted.
Here, I am going to deal mainly with scientific research. Innovation also belongs to the arts, humanities and critical social sciences, and I have plenty to say in other posts about the impact of AI in these, my ‘home’ subjects. But in these areas the AI industry tends to rely on brute force of capture and less on claims to innovation: nobody is claiming these subjects can go home and leave research to the machines. From the famous stochastic parrots essay to the Resisting GenAI in Writing principles, there are coherent arguments as well as cultural biases against the idea that statistical iteration over old forms can produce new creative or critical work. Creative workers have been among the few groups in the global North to organise effectively against the threat to their livelihoods, and theft from creatives is one objection to generative AI that is widely understood. In fact the AI industry no longer even pretends to respect creative work, attacking the laws that protect its value, and gaslighting creatives who stand up to them. Prominent among these, Hayao Miyazaki of studio Ghibli, once said of synthetic art:
‘Whoever creates this stuff has no idea what pain is whatsoever. I am utterly disgusted… I strongly feel that this is an insult to life itself.’
Still, scepticism about AI’s creativity coexists in the public mind with an absolute conviction that it is ‘revolutionising science’, and it is in scientific research that AI makes its strongest claims to transformative impact.
In research, we are mainly talking about specialised machine learning models that have been trained on a refined diet of meticulously prepared and filtered data, sometimes collected over decades, and not on the junk that goes into generic models. These models are also trained by scientists to ‘see’ the things that scientists are looking for: there are an infinite number of patterns in data, of which only a fraction are meaningful. Darren Acemoglu, an economist whose downbeat assessments of generic AI I have cited before, writes in Prospect magazine that the only hope for a positive outcome from AI is to focus on the potential of these specialised applications .Dan McQuillan pushes back on even these modest hopes. My position is somewhere between the two. I believe that expertly collated data, viewed with expertise, is often of value, but the value has to be carefully weighed against the costs, both the local costs of collecting and managing data, and training experts to work in relation to that data rather than in others, and the systemic costs of over-investing in data as method at the expense of many others - also of course the concentration of power and expertise that comes with data-intensive methods.
I previously wrote about the use of machine learning in materials science and drug discovery, where AI is predicting molecular structures in ways that may guide but do not replace the hard benchwork of discovery and testing. These ‘new’ molecules only exist in theory. And even at the molecular level, it seems now, the real world is messier than data models allow for. The much-vaunted protein-folding models get basic physics wrong and (from the same article) the ‘accuracy of these models may degrade substantially when predicting non-standard or previously unseen protein-ligand systems’. In other words, they cannot be used reliably for new discoveries. In climate change research, a recent review finds that machine learning techniques are not ‘viable alternatives to traditional numerical models’ and after decades of investment, the two approaches have still not been integrated effectively. In another high-profile case of ‘AI beating humans’, partial differential equations turn out not to have been solved after all. Even where machine learning has been used for decades to deliver efficiencies in research tasks, the benefits are in narrow parts of the workflow, results typically need to be verified by other methods, and the whole enterprise is costly. An overview recently published in Nature concluded simply that ‘an over-reliance on AI-driven modelling is bad for science’.
But the hype continues. Consider a recent headline, also from the Nature stable:

The article behind the headline provides a table of promising applications of ML in epidemiological modelling, none fully mature, and the best offering only ‘incremental’ gains. But besides overstating the potential impact, ‘help prepare the world’ recognises - without actually saying so - that it is up to other people to realise the actual benefits from any new insights. Despite the fact that ‘AI’ and indeed ‘machine learning’ have been around for 75 years, the benefits exist almost entirely in the conditional future tense, and in moving from the present diagnosis to that future solution, someone, somewhere has to do some actual work. Prediction is not amelioration, diagnosis is not cure. The gap must bridged by the mobilisation of people and resources, by investment, by embodied activities of construction and care.
And there, more precise knowledge of the problem is only sometimes useful. Public health measures, vaccine programmes and less exploitative farming practices are all preparations for the next pandemic that can be applied today, with technologies we have, and with benefits that have already been proved - even if the pandemic should not arrive. The greatest gains would come from applying these solutions in parts of the world that don’t have them already – and models are a poor fit in these left-behind regions (no resources: no data). So the problem isn’t a lack of precision in targeting, the problem is unequal resources. In fact, the big problems that AI promises to solve all have this same catch: the political and material resources to solve them still have to be mobilised.
Recall that the Bayesian statistics behind all this modelling were nurtured in the insurance industry and speculative finance, and consider the move that makes precise knowledge of the future more valuable than taking action for everyone’s greater security. Bayesian calculations certainly allow people with better predictions to make money. NVIDIA’s climate modelling behemoth Earth-2, a ‘digital twin’ built largely on public data, advertises its core users as Spire, JBA Risk Management and Climasens, all insurance and risk management corporations. With its own private satellite network, Earth-2 can be seen as a privatised double of the earth that increasingly extends into the real world in the form of data monitors and orbiting hardware, all to benefit the people who benefit from monetising risk.
The ‘good’ uses of ML in scientific research might again be thought of as new ‘lenses’ on existing data, guiding scientists to pay better attention to patterns that they in turn have guided the model to look for. Sometimes the value of data makes it worth investing in some massive shared project to collect it - think of the large hadron collider or James Webb telescope, an instrument whose history has become entangled with generative AI. But even where the new data is of great value, the concentration of that value in a single project carries risks. It tends to reduce the diversity of the research workforce and to harm the diversity of methods and perspectives, as well as (in fact, as symptoms of) concentrating expertise and funding.
Unlike the telescope, microscope or CT scanner, ML data is not being collected in real time. The lens is a historical one, and large-scale historical data sets carry additional risks of their own, that this paper identifies as: ‘representational harms’, ‘faulty science’, ‘over-generalisation/de-contextualisation,’ ‘poor labour conditions’ and ‘a lack of care for data subjects’. Philosopher Thi Nguyen reminds us that data has intrinsic limitations. To decontextualise means to choose what is worth recording as data and discard the rest. To categorise means to choose the meaningful features. To measure means to decide on the norms. ‘Data-based methods are intrinsically biased’, not accidentally so.
Entire research funding systems are now being skewed towards past data and their biases, especially in already-data-rich areas of research. A recent study on research careers titled ‘Innovations in Technology instead of Thinking?’ found that:
considerations about potential future academic revenues derived from innovative research technologies sometimes seem to override particular epistemic valuations.
Among the ‘potential futures’ and ‘epistemic values’ that may be over-ridden in the rush to machine learning are real-world experimentation and observation; the collection of data that does not fit existing parameters or categories; new contexts; methodological innovations beyond data crunching; and new theoretical paradigms - all drivers of innovation for most of the history of science. Armin Grunwald, a philosopher of technology, notes in a recent essay the ‘risk of closing down the openness and potentiality of futures to a model-driven prolongation of the past’.
And in every field where ML is prioritised as a method, the values of ML (‘Performance, Quantity, Efficiency’) produce opportunities for commercial capture. Earth data, like that collected by Nvidia’s Earth-2, is sold for commercial advantage. Google DeepMind retains the right to assetise patents arising from the use of its AlphaFold database although the data involved was all derived from investigative science. Microsoft and Google are competing to assetize environmental data, and there are intense efforts to control genetic and epigenetic data, with big AI recently investingly heavily in genomics and pharmaceuticals so that discoveries based on the DNA of people and other species can be assetised in exactly the same way as the art of Studio Ghibli.
Just as Miyazumi found AI art an ‘insult to life itself’, so the capture of ‘life itself’ as data portends new harms to all of us and to our common planet. Meanwhile the AI hype machine siphons precious resources from the foundational research and the putting-into-practice of well-researched solutions that we all need to survive and flourish.
(Not) ‘enhancing’ research
If machine learning has achieved less for research than is advertised, and at greater cost, still the generative AI industry has been desperate to associate their off-the-peg consumer products with those data-curated, expertly-trained specialist models. Lorena Barba, a professor of machine learning, collects examples of such hype and has rather wonderfully classified them as: ‘performance claims out of context, renaming old things, incomplete reporting, poor transparency, glossing over limitations, closet failures, overgeneralization, data negligence, gatekeeping, and puffery’ (Barba 2023 n.p).
With such a fine-grained bullshit detector available, there is really no excuse for universities to buy it. Leon Furze has done a great job of evaluating the so-called ‘deep’ research capabilities of generic LLMs (and if you don’t already subscribe to his work, you really should), concluding that they may be OK ‘for businesses and individuals whose job it is to produce lengthy, seemingly accurate reports that no one will actually read’. Anyone who engages with student writing at any level will be familiar with the miasma of credibility effects produced by these so-called ‘research’ models: fluent summaries that include real sources, though the summaries are repetitive and over-generalised and the real sources rarely say exactly what they are supposed to say. More than two years after Ted Chiang found that ChatGPT is a blurry jpeg of the internet, the billions spent on tuning it for ‘research’ effect have made it a blurry jpeg of Google Scholar, while simultanously turning both sources to absolute crap.
Research is not a general purpose activity and there is no general accelerant you can apply. A recent preprint explains that ‘The promise of foundation models relies on a central presumption: that learning to predict sequences can uncover deeper truths, or optimistically, even a world model.’ Cleverly, the authors devise a series of ‘inductive bias probes’ to test this presumption with Newtonian physics (and if you are thinking: ‘why didn’t they just ask the AI to explain Newtonian physics?’, please read my piece on why AI is not reasoning, and how very difficult it is to find out what it is doing at all). The ‘related work’ section of this article is particularly thorough and convincing. What the authors found, repeating findings from a host of other studies, is no. There is no deep understanding. There is no world model. There is just a ‘bag of heuristics’.
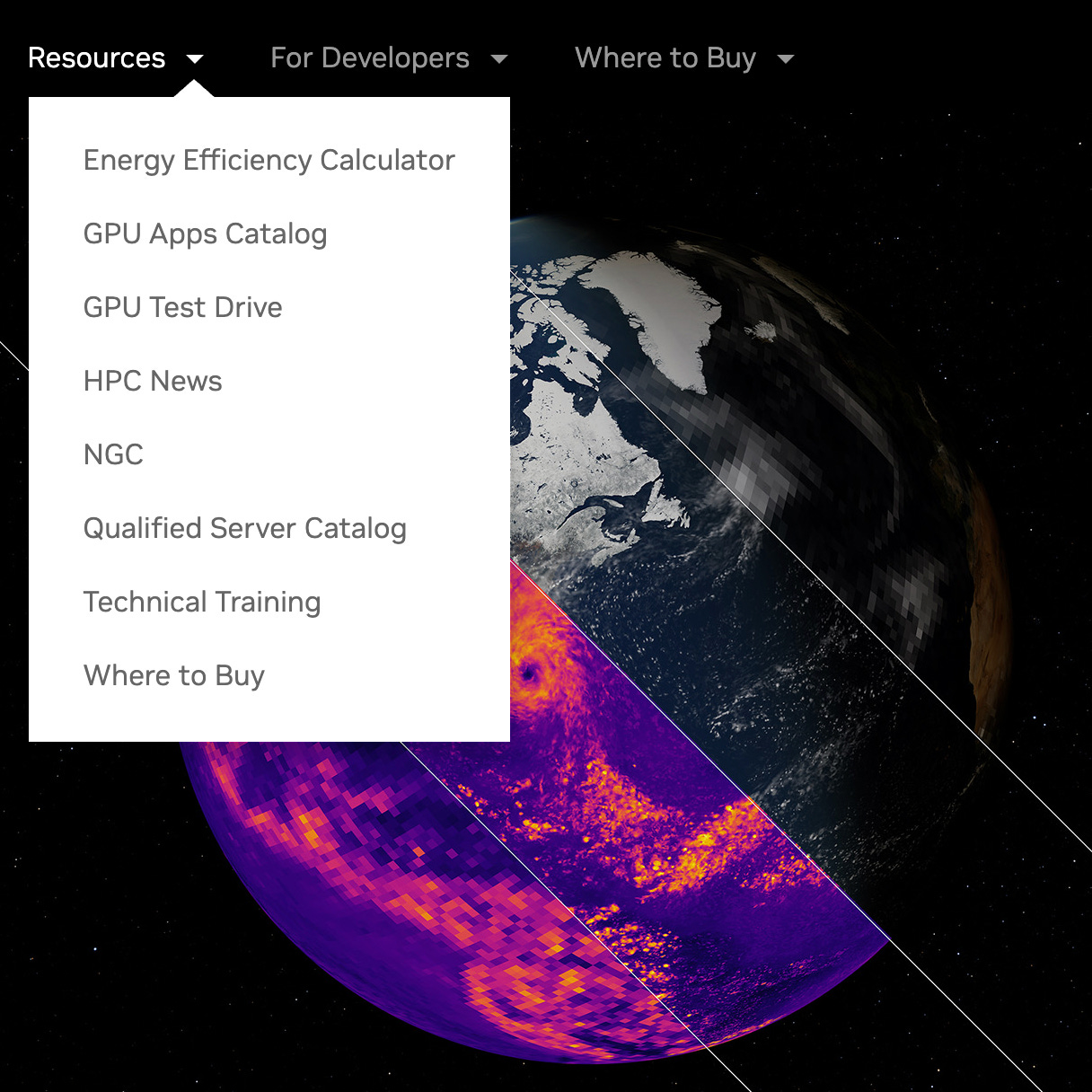
Nonetheless, the last year has seen a flurry of surveys from academic publishers – mainly the ones that have just sold our life works to big AI – purporting to show that researchers are excited about the opportunities of AI in research. Most of these surveys are so biased in design and so dishonest in reporting that I can’t in all conscience bring them to your attention, but despite a misleading headline and an odd discrepancy in the figures, Oxford University Press has passed on its results with good candour. Among its researcher participants (n= 2345), 27% claimed to have ‘benefitted from AI’ (not the 36% reported) and just 5% of these - a little over 1% of the total sample - mentioned using it for their ‘own work/analysis’. The other ‘beneficiaries’ had used it for research-adjacent tasks such as ‘to write more polite emails and to think of cool titles for my papers’.
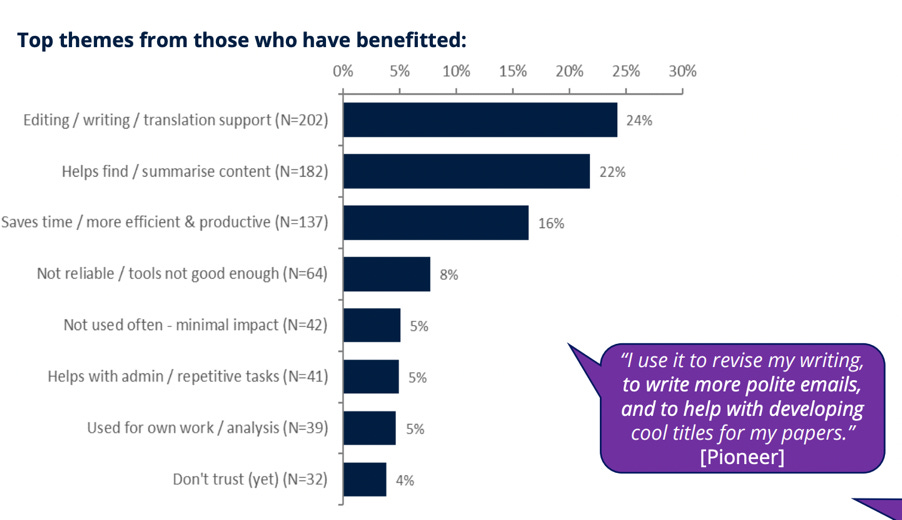
Of the eight clusters of opinion identified in the OUP report, 933 researchers were negative about AI in research - it’s not obvious why this group has been split four ways. Another 811 were undecided, though we don’t know how this group weighted ‘saving time’ and ‘excitement’ against the rather more research-relevant factors of ‘distrust’ and ‘concern’. Just 345 were positive overall about the impacts of AI on research, and in true ‘frontier’ spirit these were labelled ‘pioneers’ rather than, say, ‘careless optimists’ or ‘reckless corner-cutters’.
Surveys of this kind deal in belief, and researchers are not immune from having their beliefs shaped by the direction of research funding, or by academic social media with its relentless FOMO, or indeed by surveys of their peers. And if your research goal is to publish an early AI use case in your field, you can probably get support from your institution and perhaps even industry partners to do this. Your local case study can be cautiously positive while your introduction and discussion project all kinds of opportunities into the future conditional tense, in which there is always room. There is little evidence that these cases do scale up beyond the favourable scenarios to which early adopters have applied themselves, but there are certainly rewards for producing them.
Titled ‘AI is revolutionizing science’, a recent report notes that ‘mentions of AI’ in published papers rose ‘from ten to thirty percent’ between 2015 and 2019 and that: ‘papers mentioning AI n-grams were roughly twice as likely to be a “hit” [highly cited] within their respective fields’. We can only assume these effects have been amplified since this work was done. Higher ‘mentions’ are glossed throughout this report as ‘AI benefits’, as though citation statistics are the benefits of research – a little like grades being the benefits of study. And just like in AI-generated literature reviews, ‘mentions’ must be pumped for all they are worth. Because generative models don’t attach qualities to instances, or explanations to correlations, so mentioning is their only move and counting mentions their only power.
For those whose research is not being boosted by AI ‘mentions’, the harms to research quality are now impossible to ignore. Those sharp AI commentators, Arvind and Sayash, recently asked the apparently paradoxical question ‘could AI slow down science?’ and concluded that yes, for all the frenzied activity, there is an overall drag on science as a shared system.

{kind=link}
Because as well as cutting out all the parts of research that actually advance human understanding, AI is crapifying the shared systems that research depends on. There is an epidemic of fake research, fake citations, fake peer reviews, and whole fake research topics (‘vegetative electron microscopy’ anyone?). Google Scholar is flooded with AI-generated slop; academic publishers and editors are overwhelmed by AI-generated papers and even AI researchers; there are threats to the viability of archives and a creeping influence on library catalogues where the use of AI in metadata creation is now widespread. Open knowledge projects including Wikipedia, source of most actually useful AI content, are being drained of funds and even taken offline by AI crawlers, and the supply side of intellectual labour is failing. The peer review process, is corrupted by AI and now by cynical manipulation of the corrupt AI review system (this last link is to a study of papers in computer science that found hidden text prompting AI reviewers to provide only positive reviews).
There are calls of course to move to a 100% AI review system, because for every AI fail there must be an AI solution. And if AI could reliably provide that it would just be an extortion racket, but since it can’t, it’s more like paying the extortionists to burn your house down.
Love and appreciate your work, Helen. This one has been particularly rich in your commentary and curation and I just wanted to say THANK YOU so much for putting all this together ❤️