


Turing's unreliable test
And what it has to do with learning

This post started out as part of a webinar about student writing, which is where I began thinking about ‘passing’ as a central concern of the AI project. (You can find the recording of the webinar here and a post on student writing as ‘passing’ here). In this post I take a wander through behaviourism and functionalism, gender and identity, statistics and IQ tests, before coming back to student learning. I touch on issues of colonial and race violence, and ‘corrective’ therapies for homosexuality, and if these are likely to be difficult for you to read about please consider choosing another post.
Serious games
The Turing test is a thought experiment that remains at the heart of the ‘artificial intelligence’ project. In ‘passing as human’ it provides that project with both a rationale and a metric of success, as per this entry in the Stanford Encyclopaedia of Philosophy. It does not provide a definition. That was first attempted by John McCarthy in 1955, who called AI ‘the science and engineering of making intelligent machines’. Marvin Minsky, in 1970, reiterated that: ‘Artificial intelligence is the science of making machines do things that would require intelligence if done by men’. ‘Intelligence’ here is a positive value applied to certain ‘things… done by men’. More recently (2023) Marc Andreessen has continued to treat intelligence as a simple value sign: ‘Intelligence makes everything better. Smart people and smart societies outperform less smart ones on virtually every metric we can measure’. Smart people don’t even have to be men these days, they just have to be better than other people at doing the things that count.
The things that count are not defined in Computing Machinery and Intelligence, the 1950 essay in which Turing’s test first appears. The essay is more interested in minds than intelligence, and more interested in machines than in minds, and more interested in games than in definitions.
Turing had spent World War II helping to decipher German intelligence using a combination of cryptography and the earliest electromagnetic computers. The battle between the UK’s Ultra project and Germany’s Enigma machines turned computation from a branch of theoretical mathematics into an intelligence arms race. Though deadly serious, the code-making, code-breaking tussle was also a kind of game. One with simple rules, but so many possible combinations that only the new ‘computing machines’ could calculate them fast enough. Winning at this game was a personal triumph for Turing, as well as an important advantage to the Allies. It vindicated much of his earlier theoretical work.
Two elements of that work are important for understanding the Turing test. One is Turing’s model of the ‘computing machine’, a kind of universal algorithm (‘a single machine that can be used to compute any computable sequence’). As early as 1936, Turing had imagined such a machine being realised in practice as a read/write automaton with an infinitely long piece of paper or tape. But the physical manifestation of the machine doesn’t really matter. The ‘machine’ is the algorithm that controls it. Any problem that can be represented symbolically and broken down into computable steps can be represented as a Turing machine. This is the simple idea behind modern computation.
A second feature is Turing’s interest in mental contests. His machine was most useful for solving problems with clear rules and many possible moves. This produces a problem space that can be expressed in concise algorithmic terms but has too many possible states or solutions for people to easily hold them in mind (people tend to fall back on other strategies in this situation). A game also has a definite endpoint (winning), and without that, knowing when a good solution has been reached is something Turing machines struggle with. It’s called the ‘halting problem’.
Games like chess and international codebreaking don’t demand a good solution for everyone involved, or a good enough solution for many occasions, or a beautiful and pleasing solution. They only demand a sequence of moves that can win.

The men who devised the earliest computers were steeped in a culture that valued such contests. In fact the competitive world of cybernetics research was itself such a game, and the term ‘artificial intelligence’ was invented by one tribe of cyberneticists as a move against another in the fight for funding and reputation. Although they could not agree on computational tactics, the players all assumed that logic puzzles and games represented a kind of universal language of thought. An early (1947) version of Turing’s test was even devised around a game of chess:
Two rooms are used with some arrangement for communicating moves, and a game [of chess] is played between C and either A [a proficient chess-player] or B, the paper machine [a written set of rules for responding to different positions and plays]. C may find it quite difficult to tell which he is playing.
It doesn’t matter that player B doesn’t understand the rules of chess. Player B is just dumbly following an incredibly clever and complicated algorithm. Turing, a keen chess player, even developed such an algorithm, on paper, in 1951. In this early paper, he seems to have anticipated the Chinese Room argument, an objection John Searle would make to the Turing test. Searle argued that a person shut in a room could, given enough time and sufficiently complex rules, translate Chinese words, character by character, into English words. But that person wouldn’t be able to speak or understand Chinese any more than Turing’s Player B can play chess. To which Turing would presumably have responded: ‘So what?’ The simulation or appearance of intelligence – passing as a player of chess, or a speaker of Chinese – is all we can objectively know.
Rat boxes and child-machines
To understand what Turing’s test or game has to do with learning, we can turn to another development of the early 1950s. Just as Turing’s essay was a founding text of computer science, BS Skinner’s 1954 essay ‘The Science of Learning and the Art of Teaching’ was a founding text for behaviourism. In it, Skinner laid down instructional methods for schools based on the principle of ‘operant conditioning’ or managing behaviour through stimulation and reward, something he had done with great success using rats.
The emphasis in this research has not been on proving or disproving theories [of learning] but on discovering and controlling the variables of which learning is a function. This practical orientation has paid off, for a surprising degree of control has been achieved.
(BS Skinner, 1954: 50)

In Skinner’s philosophy, learning meant optimising behaviour. The emerging science of computation was similarly interested in optimising algorithms to produce desired outputs efficiently, often (as with behaviourism) by breaking tasks down into incremental or computable steps. Turing’s essay includes a digression that makes the link between computation and behaviourism explicit:
We normally associate punishments and rewards with the teaching process. Some simple child machines can be constructed or programmed on this sort of principle… I have done some experiments with one such child machine, and succeeded in teaching it a few things. (Turing, 1950)
In rat boxes and computer systems, ‘desired’ behaviour is determined by someone outside the system - experimenter, educator or programmer - who also devises the reward/punishment regime. The learner, computer or ‘child machine’ has no agency in this regard. In fact the subject of the test can be expressed as a function of the system: the probability of producing the desired or ‘appropriate’ behaviour in response to the relevant stimulus. And here is another similarity. A significant goal of the behaviourist project was to reinvent psychology as a statistical science. Skinner’s optimised behaviour was expressed as ‘the probability that appropriate behavior will, indeed, appear at the proper time’ (1954: 51). Turing’s test is also probabilistic. His prediction, specifically, was that by the end of the 20th century:
‘an average interrogator will not have more than 70% chance of making the right identification after five minutes of questioning’
So the Turing test established a precedent for treating system outputs as evidence of ‘intelligence’, at the same time that Skinner was teaching educators to treat learning as behavioural optimisation. Both expressed behaviour as probabilistic functions of systems. In fact, both are examples of extreme functionalism. Refusing to see minds as embodied, culturally-situated, or inter-related, they also gave up on minds as having motives, desires or beliefs, or at least on the idea that anything could be known about them. It could be argued that they gave up on minds altogether in order to focus on prediction, optimisation and control.
In his rather odd aside about the child-machine, Turing seems to anticipate a key feature of large language models today. They are optimised by statistically rewarding or ‘weighting’ states of the model that produce the desired outputs. Remember the ‘halting problem’ for the Turing machine? The vastly more complex, multi-layered transformer models of today still have a problem knowing when their solution state is good enough. With no goals or interests of their own, they are dependent on system engineers to decide their trajectory and provide the appropriate statistical nudges.
As Turing said of his child-machine:
its teacher will often be very largely ignorant of quite what is going on inside, although he may still be able to some extent to predict his pupil's behaviour.
This learner is the very definition of a black box in systems theory. Under a regime of pure functionalism, the equation of a person with a machine, a mind with a computer, makes perfect sense.
Let’s meet the players
In Turing’s thought experiment, the equivalent of Skinner’s rat-bothering scientist is called the interrogator (Player C). This player’s role is to question the subjects, who are a computer (Player A) and a human responder (Player B), and to judge which is which.

The players are behind some kind of screen, their bodies and voices hidden, their responses limited to the passing of text messages. The human being in this scenario is already something like a Turing machine with its read/write interface. The equivalent positions of human and computer, the insistence on disembodied ‘outputs’ and the comparative nature of the judgement are all used as signs of the test’s objectivity. But if we look deeper, it is a maelstrom of power play and cultural assumptions.
First, producing a computer that behaves like a person is treated as an obviously desirable goal for computer science. What kind of a desire is this? Whose desire is it? Then there is the role of the ‘interrogator’, who must first elicit behaviour and then decide: ‘does this behaviour imply to me that a mind is at work, given my own experiences of having a mind, and interacting with other minds? Do these responses make sense in light of how I understand the rules of the situation, and how I imagine another person (with a mind like mine, perhaps?) might interpret them?’ Turing himself remarked that:
The extent to which we regard something as behaving in an intelligent manner is determined as much by our own state of mind and training as by the properties of the object under consideration. (Turing (1948) p. 431 –cited by philosopher Diane Proudfoot.
Earlier, in Gods, Slaves and Playmates, I wrote about the ‘states of mind’ that make us all susceptible to regarding computers as intelligent. Intelligence, sentience, meaning-making, I argued, were all in the mind of the beholder. The beholder here is the judge. And I notice that Turing naturally identifies with the judge himself, not doubting his ‘own state of mind’ as something real and knowable and capable of complex judgement, nor his right to ‘consider’ and ‘regard’ the other players as ‘objects’.
If we now imagine the judge as an academic assessor confronted with two student texts, we can also see why there might be a need for ‘training’ in the role. Identifying synthetic text is difficult. It depends on (among other things) experience, thoughtfulness, a sound understanding of the writing process, and (preferably) of the individual student as a writer. And the demand for academics to exercise this kind of judgement is changing cultures of writing and assessment, changing what it means to write, and changing relationships among academics and students. So there really is no simple heuristic that can be applied.
The kind of mind required to play the judge’s role is not recognised in behaviourist accounts of psychology, nor modelled in any algorithm. But this kind of mind - empathic and reflective, subtle and cunning, culturally situated and distracted by its own desires and biases - is hiding in plain sight in the role of the judge. And behind the judge, in the role of the system designer, who has made the rules of the game.
As I have argued elsewhere, hiding the culturally specific, embodied work of human judgement has always been critical to producing systems that can ‘pass’ the Turing test. The original ‘mechanical turk’ hid a human operator in its wooden skirts.

Today’s large data models hide the expert judgements of model engineers in ‘parameterisation’. The judgements of annotators and data workers are swept up into the ‘data engine’ and once again removed from view, as noted in my piece on labour in the middle layer and recorded extensively in the book and web site GhostWork. Judgement – by definition culturally specific and subjectively located– becomes data, apparently objective in its categories and classifications and measures of value.
Assessing intelligence
As well as hiding the fact of judgement and its partiality, AI systems also ignore the power of judgement and the consequences of being judged. At the time Turing wrote The Imitation Game, written responses to test questions were widely used in Europe and America to determine what kind of person you were, what kind of life you could lead, whether you could get work, or housing, or cross a border, whether you served as an officer or a combatant. Collectively, the outcomes of written intelligence tests were used to justify the last insults of retreating colonialism, immigration quotas, racial segregation, forced sterilisations, and the removal of indigenous children from their families. Deciding who was (what kind of) ‘human’ and who was not was a deeply political question, but it was a politics that was projected through statistical methods.
Alongside behaviourism, UK and US psychology was dominated by eugenicists like Cyril Burt and Hans Eysenck, who designed and popularised IQ tests, and who were even more influential than Skinner on the management of schools. Given their origins in race science, it is no surprise that the statistical techniques of IQ testing found white people more intelligent than brown and black people, children of bank managers more intelligent than the children of manual workers, men more intelligent than women, and settlers more intelligent than indigenous people. Over three decades, Burt published a series of hugely influential twin studies that seemed to show that:
Intelligence is all-round intellectual ability. It is inherited, or at least innate, not due to teaching or training; it is intellectual, not emotional or moral, and remains uninfluenced by industry or zeal; it is general, not specific, ie. it is not limited to any particular kind of work, but enters into all we do or say or think.
Education’s task was not to try to overcome these ‘natural’ differences in ‘all we do or say or think’ but through regular testing to sort pupils into the schools, streams, programs and life courses that best suited their innate capabilities.
Burt’s work was later shown to be deeply flawed, and in some cases deliberately faked. But we are still living with the impact of standardised testing on educational practice and the over-use of statistical methods in educational research. (Has someone tried administering IQ tests to ChatGPT? Of course they have.) Arguably, today’s proponents of ‘human enhancement’ are drawing on similar ideas to those earlier eugenicists: the general nature of intelligence, and the perfectibility of (at least some) human beings through genetic means.

Futurist and Musk favourite Nick Bostrom, for example, argues that ‘superintelligence’ will require genetic as well as cognitive enhancement. And Elon Musk’s own deeply problematic experiments with brain implants are intended not only to ‘fix’ sensory disabilities but (in his words) to ‘elevate intelligence’ for ‘regular’ people.
Turing, of course, did not claim to define or measure intelligence, let alone to enhance it. His test is on the face of it a qualitative encounter. The judge can ask any question, not confined to maths, chess and logic. It is a thought experiment, not a standardised test. But it remains an intellectual touchstone. The test is perennially claimed to have been ‘passed’ or ‘broken’ in some capacity or another, rewarding believers for their faith while demanding further investment in the search for an ‘artificial general intelligence’ that will pass better, and more comprehensively, and is always just over the horizon.
Why is the Turing test such a potent enabler of AI’s claims? I think it is down to its flexibility, allied to its extreme functionalism. It reduces human capabilities of all kinds to manifest behaviours or ‘plays’, and limits these plays to what is currently computable in order for humans and machines to be compared. In the classic Turing set up this meant disembodied text. Today a screen-based avatar could fulfil the role. But the rule remains: human players must be rendered computable for the test to be possible at all.
The test relies on the subjective judgement(s) of a mind that is pre-designated ‘normal’ (‘an average interrogator’) and so is located outside of judgement - no doubting that this is a mind, or that its judgements are real. The system then hides that mind and its judgements, its subjectivity, its cultural specificity, its human fallibility and its power, in a probabilistic score. A score that can stand in for judgement as an abstract procedure. Over 70 years, all these elements of the test have been critical moving parts of the AI machine.
Kinds of people
Returning to Turing’s original essay, we can now see that it is at least as interested in classifying people as it is in differentiating people from machines. And it is particularly interested in classifying people by gender. The first ‘imitation game’ outlined in Turing’s essay is in fact a parlour game in which the ‘interrogator’ (player C) must try to discover which of two players is a man (player A), and which is a woman (player B). The man is trying to trick the judge. From the examples given this clearly involves pretending to be a woman. The woman is ‘just being herself’, as women must (‘I am a woman’, she says helpfully). The set-up is really a contest between two men, A and C, in which ‘acting like a woman’ and ‘detecting a fake woman’ are the main plays, and the woman (B) is little more than a counterpoint.

The essay was written at a time when Turing was under intense pressure himself to ‘pass’ as a ‘normal’ (straight, cis) man. Pressure that the British state would soon exert by the method of forced administration of a ‘chemical castration’ hormone, after Turing’s arrest for indecency in 1952. It is widely believed that these pressures contributed to his suicide in 1954. While we can’t know for sure what the parlour guessing game meant to Turing, we can ask whether anything he wrote in 1950 about ‘passing as’ a man can be taken at face value. Perhaps, at least, his essay reveals something of the real jeopardy behind the game.
When the computer is first introduced, it is in the place of the man (player A). But player B slips from being a woman to being a man, now in the passive position (that is ‘just being himself’) between page one and page two of the essay. The long entry on the Turing test in the Stanford Encyclopaedia of Philosophy only mentions these gender confusions about 3000 words in, under the heading ‘minor issues’. But let’s at least allow that the question ‘who is the man?’ – the question that crosses over from the first version of the imitation game to the second - is a question about ‘kinds of people’ as well as a question about computers and thinking.
Taken together, Turing’s two games seem to generate a host of further questions. Questions like:
How does one pass as a (gendered) person?
If we remove bodies from the scene, what is a (gendered) person?
Is the mind gendered?
What happens to a man (or woman) who fails to pass?
In fact, what pretends to be a system for generating probabilities and classifications is actually generating a host of questions about identity, that in turn produce norms and anxieties about how to behave as a person (of a particular gender, race and class). These issues could hardly be more culturally loaded or more political.
Read in its entirety, Turing’s original essay shows how assessing the ‘humanity’ of a computer program can’t avoid establishing norms about ‘kinds’ of people and their ‘proper’ behaviours. Data systems are used today to make highly consequential decisions about kinds of people. Image generation and facial recognition systems are trained on human-categorised data that is race, gender and sex biased. FRCs make more and more identification errors the further a face departs from a white, middle-aged, cis male ‘norm’. ‘Structured decision making’ systems have led to many indigenous children being taken from their families. Multiple surveillance systems including facial recognition (again) are used to select people (including academics) for targeted bombing in Gaza. There is now extensive work (e.g. Lupton and Williamson 2017, Williamson et al. 2020, Beetham et al. 2022) on the way surveillance and analytics in education render students as data subjects, categorised as ‘kinds’ according to behavioural and demographic features, as well as how they interact with diverse data systems.
Who judges the judge?
There is one more twist in the story of the Turing test. Today’s massive data models, as I have already noted, are ‘refined’ after initial training using ‘reward models’ or ‘preference models’. These are secondary statistical models, constructed from human feedback on the primary model.
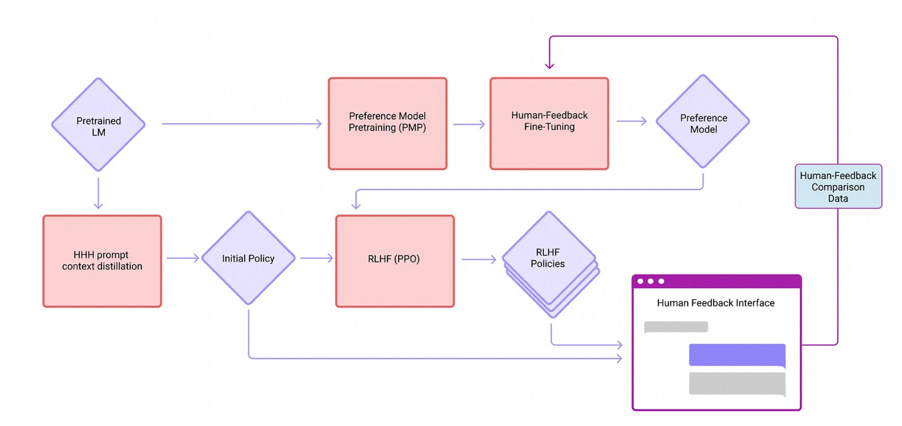
It is relatively expensive, for example, to employ educational experts to give feedback on tutoring models, or coding experts to give feedback on algorithmic models. As it becomes clear that (re)training is not a one-and-done process but requires constant iteration, a reward model cuts down on these costs and maximises the retraining advantage.
Now that generative models are competing for share of an extremely lucrative business market, performing well on evaluative benchmarks is also critical to achieving market share. But benchmarks are themselves statistical models of qualities previously judged by human experts such as ‘acceptability’, ‘truthfulness’, ‘coherence’ and ‘reasonableness’. Benchmarks are, in effect, statistical aggregates standing in for Turing’s ‘average interrogators’. Like all statistical models, they are partial, over-specified and unreliable in new contexts. They are also being extensively gamed. As new benchmarks emerge (and this, too, is a competitive business), they are incorporated into the training process. Data contamination is inevitable: models perform well on benchmarks simply because they have ingested the same contents and statistically weighted them in the same way. Without regular injections of human expertise, models trained by other models can degrade and even collapse.
We can think of the Turing test as a machine for reducing a complex social interaction to a single number: the probability of Player C mis-identifying players A and B. In computational terms this probability is identical to the difference between the answers A might give, and B might give, to the same question. The computer (A) is trained on as much question and answer data as possible to bring this difference close to zero. Meanwhile the judge (C), now also a computer, is trained on the same materials in order to make more and more finegrained assessments of the difference that remains. The role of B, the human in the loop, like the woman in the original parlour game is simply to provide a source of comparative data. Between A and C there is something like an arms race of statistical scale. We can exactly same arms race between ‘AI’ in assignment writing and ‘AI detection’, with real student texts becoming sources of data for both sides.
What started as a complex, qualitative dance becomes a contest of brute power between two judges who think almost exactly alike. No wonder it has been suggested that the Turing test could these days be replaced by a simple test of computing power. Mustafa Suleyman, CEO of Microsoft AI, has argued for the Turing test to be replaced by a metric that even more perfectly reflects what ‘winning’ means in AI: ‘how much money can ChatGPT make?’
Black boxes and hidden desires
Benjamin Bratton, writing in 2015, suggested abandoning the Turing test as an ‘anthropocentric fallacy’. He argued that:
Airplanes don’t fly like birds fly, and we certainly don’t try to trick birds into thinking that airplanes are birds in order to test whether those planes “really” are flying machines. Why do it for A.I. then?
Under the Turing test, definitions of ‘artificial’ as an analogue of ‘human intelligence’ only refer to functional similarities. They ignore structural features, such as architectures that might mimic the neural structures of the brain, or symbolic computer languages that might replicate the syntax of human reasoning. I do not agree that these structures are analogous, but I do think there is a real research agenda here. Tracing meaningful connections between structures and functions is what the science of cognition proposes. It’s how the science of powered flight discovered the aerofoil and gave up on flapping wings.
Bratton diagnoses that the Turing test is a trick. But he fails I think to recognise that the trick is necessary. If, like Bratton, you want to define AI without anthropocentrism, you need a definition that doesn’t depend on human meaning or judgement or values, not even statistically modelled versions of them. You might then provide better descriptions of the systems from which complex outcomes emerge –‘better’ as in more open to the tools of research and the resources of critical thought. It would be a good thing, I think, for everyone who wants to use AI systems in an informed and ethical way. But to construct today’s really existing AI systems, you need to accord some outcomes, some system states, more value than others. That is how todays large media models are trained, by backpropagation towards a desired state. ‘Intelligence’ is the value associated with this state. And ‘Artificial intelligence’ is the goal of reproducing this value computationally.
Without this analogy and desire, all you have are diverse computational techniques. And it is doubtful that any of today’s techniques would have been developed without the immense investments of data and capital, engineering and future imagining that desire has been able to mobilise. (A recent report on the advances in generative AI since 2012 found that scaling up compute has been significantly more important than any algorithmic advances.) AI fantasies may be ‘for the birds’ but they are still what keep the plane in the air.
When I studied AI in the 1980s, it was science and philosophy of science that interested me. Attempts at developing human-like responses in computer systems, particularly when those systems were designed in dialogue with philosophies of language and mind, seemed to me to promise explanations that traditional philosophy could not. Making things work brings a materialist rigour to speculative thought. That is what Bratton is also interested in. He hopes that the search for viable AI might lead to ‘a fuller and truer range of what thinking can be (and for that matter, what being human can be)’. But that research project has been thrust aside in the rush to monetizable outcomes, as many cognitive scientists besides Bratton have lamented. Making things cannot lead to understanding if you don’t understand what you have made. Again, this is not a defence of traditional cognitive science, but an observation that on its own terms, the performative turn is a dead end.
Black boxes are anathema to science. But in contemporary AI, it’s black boxes all the way. First, models are proprietary (so, secret). Second, approaches that might enhance explainability are expensive, and nobody important (that is, nobody who is paying) really wants them. Third, the training process is so complex, the resulting data structures so multi-dimensional and many-layered, that explainability lags many years behind model development. Explaining a model once it has been trained is not like pulling back a curtain, but like taking echo soundings from an ocean floor: a range of ad hoc and uncertain techniques that might produce a ghostly outline. There is a school of thought that the Bayesian statistics large general models are based on may even be inherently non-explainable.
In a remarkable book on computers, chess and minds, Gary Kasparov said of his defeat by supercomputer DeepBlue that: ‘the machine doesn’t have to solve the game. The machine only has to win’. Winning, in the AI game, is everything. As I’ve mentioned before, generative transformer models are based on statistical methods honed in the insurance industry and in market analysis, where they are used to manage risk and to predict future areas of profit. How much money can ChatGPT make? It seems like the kind of metric it should excel at.
The economist Frederich Hayek saw markets as algorithmic systems, distributing economic goods in the only rational way. Nobody needs to understand or regulate the market: everyone just needs to get on with doing their profit-maximising thing and the market will find its own best state. There is a direct intellectual line from Hayek via libertarian economists such as Peter Bauer and Peter Brimelow all the way to today’s alt-right, taking in many proponents of ‘scientific race’ theory and heritable IQ along the way (these links are to recent articles by Quinn Slobodian, who has this whole connection nailed). You can hear Hayek’s passion for free, unregulated, algorithmic markets in Marc Andreessen’s plea for AI to be ‘set free’.
Like the brain-computer analogy, the computer-market analogy works both ways. It allows behaviour to be modelled mathematically, in terms of maximising outcomes, which is an efficient way of managing complex human and social issues if you are looking at them from on top, or from a long way away. And it allows markets themselves to be seen as the apex of rationality, obscuring their unruly desires, their regular crises, the injustice and violence of capital accumulation, and the planetary death drive of capitalist growth.
In the neoliberal university, learning too can be understood in economistic terms. Maximising outcomes becomes the only rational path for learners to take through the system, and behaviourism the only rational theory for educators to apply. If teachers are encouraged to treat learners as black boxes - probabilistic functions of inputs and outcomes - and if learners see teachers as capricious judges who stand between them and the degree they have paid for, it makes sense for both sides to recruit synthetic media to improve their play. I have a post on ‘writing as passing’ that looks deeper into this dynamic, and tries to think creatively about writing beyond the production line.
Reading Turing differently

What of Turing? Though homosexual ‘behaviour’ was decriminalised in 1967, and Turing himself received a state pardon in 2013, members of the psychiatric profession including Hans Eysenck were arguing for criminalisation and chemical castration well into the 1980s. Behaviourism, and a psychiatry focused on producing ‘normal behaviour’, led to the kind of corrective ‘therapies’ that cost Alan Turing his happiness. IQ testing contributed to decades of racialised and gendered discrimination, classification and control. And probabilistic methods in AI continue to classify ‘kinds’ of person in ways that are inherently biased towards a particular ‘norm’ - sexualised, gendered, racialised - and oriented towards surveillance and discipline.
Had Alan Turing lived through the political upheavals of the 1960s and 70s, and been able to reflect on the impacts of behaviourist psychology on many lives besides his own, I like to think he would have come to question the use of his thought experiment as a performative test for ‘passing’ as a human being. Today his name is more happily associated with a clause in British law that allows people convicted of homosexual ‘behaviour’ to have that conviction removed and to negotiate their identities and desires as they choose.
These messy question of politics, identity and desire are exactly what computational ‘intelligence’ is supposed to lead away from. AI is meant to offer accuracy, objectivity and control. The problem, of course, is that politics is not removed but installed in proprietary systems where it can’t be brought into the light of day, or questioned, or resisted. Power, desire, and the desire for power are parameterised. The judge in the Turing test, the ‘teacher’ of the child-machine, the model engineer and the designer of the ‘reward engine’ still have all the power to determine people’s ‘kinds’ and people’s futures, but none of the accountability that politics might demand of them.
"Refusing to see minds as embodied, culturally-situated, or inter-related, they also gave up on minds as having motives, desires or beliefs, or at least on the idea that anything could be known about them. It could be argued that they gave up on minds altogether in order to focus on prediction, optimisation and control.
[...]
The equivalent positions of human and computer, the insistence on disembodied ‘outputs’ and the comparative nature of the judgement are all used as signs of the test’s objectivity. But if we look deeper, it is a maelstrom of power play and cultural assumptions."
As other commenters have pointed out, linking 'passing' with the Turing test to gender is really insightful. I also love the way, in the bits I've pulled out above the way that you've shown how reliant disembodied GenAI is on embodied congnition.
Great stuff. I hope you're working on a book version of your essays, at the very least!
Thank you. You have given us a lot to ponder in this essay. The gender aspect is one I hadn't considered in this regard.