


Human work, GenAI and Mechanical Turks
A journey through the labour pyramid that is Generative AI, and some thoughts on teaching

Ask ‘what is GenAI?’ and you will get different answers. That’s true of any technology in social use, because social life is complicated and technology faces different ways – to its designers an artefact, to its users a tool, to its owners a source of revenue, and to all of us a new set of relationships. A couple of times I have made the claim that foundational models such as GPT-4 can be seen as platforms for coordinating labour, especially the work of producing text. This post is where I work out what that might mean.
Treating GenAI as a platform doesn’t directly address the questions of whether it is ‘artificial’, or ‘intelligent’, but indirectly it might help to qualify both those terms. I think of a platform the way Nick Srnicek describes it in Platform Capitalism to mean ‘digital infrastructure that intermediates’. A platform:
‘positions itself (1) between users, and (2) as the ground upon which their activities occur, thereby giving it privileged access to record them’
And in recording them, to extract value. GenAI is already so widely and deeply integrated into other platforms and services, we may soon have to consider it less as a discrete platform and more as a stack, in Benjamin Bratton’s terms:
‘an accidental megastructure, one that we are building both deliberately and unwittingly and is in turn building us in its own image.’
But on our way to the full-stack AI lifeworld, GenAI’s foundational models are still visible as a new set of labour relations, of ‘intermediations’, coming into being.
In the case of GPT-4 these relations are coordinated through a vast, specially-built (Microsoft/OpenAI partnership) supercomputer network, the material infrastructure that determines who ‘owns’ and profits from the labour it coordinates (answer: Microsoft and OpenAI do). The infrastructure itself represents a massive concentration of economic value: the labour of all the miners and logistics drivers and Taiwanese and Korean factory workers who together make the tens of thousands of NVIDIA AI-optimized GPUs (processors) that form the GTP-4 network. Then there are the workers at Microsoft’s Azure data centres, servicing their massive cooling systems and vast power supplies and backup generators. Initial training of the GPT-4 model took at least 3-4 months, meaning that the ‘compute’ required at this stage alone required an estimated 7.5 megawatts of electricity. That was generated somewhere too.
The labour of writing magicked into data
But I’m interested here in creative labour, and particularly the labour of writing. Starting with what is termed ‘training data’ but is actually the material that the model is built from. When OpenAI released the system card for GTP-4 earlier this year, they offered:
‘no details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar’.
‘Safety’ and ‘competition’ were given as the reasons. So we don’t know everything that’s in GTP-4’s training data, but we do know (like earlier GPT models) that it includes CommonCrawl, BookCorpus and Wikipedia. Each of those corpora represents billions of hours of human work. Writing for the web (not necessarily well considered). Writing for publication (much of it still in copyright). And writing for publication on the web: all of wikipedia’s volunteer authors, editors, reviewers, content managers, and governors, many of them academics and students in higher education. Every gigabite of textual data that GPT-4 was built on - the good, the bad, the biased and the ugly - was produced by someone. Someone who thought they were writing to be read, not to be data.
Mathematical magic
GPT-4 started life as a transformer architecture that developed as a model only as it went to work on all this textual data. (You can skip this part if you are all over what that means; also if you don’t know and don’t care). First the text is cleaned and broken down into tokens – discrete words, word parts, and word embeddings: information about where a word comes in a sentence, for example. In the ‘unsupervised’ or pre-training stage, relationships among the tokens are mapped. These are probabilistic relationships: how probable is it that one token will be found in close proximity to another one? ‘Close’ need not mean very close here. GPT-4 can map relationships across a sequence of text (or context window) as long as 32k characters.
Like all transformer models, GPT-4 processes information in many layers and over many iterations. At each pass over the data, the parameters that describe the relationships of tokens are refined. As well as tracking connections across long sequences, training assigns a different weight to different parameters. When generating a new sequence, the transformer will use these weights to ‘attend’ to some parameters more than others: some words, in some positions, influence the probability of the next word more than others do. What the GPT-4 model consists of, once the training process has converged on a stable state, is around 100 trillion parameters of data, all expressing relationships among tokens in the corpus text, and associated weights (this piece on Anita Kivendo’s blog provides a more technical summary than mine).
Although the maths is extraordinary, the model is not just whirring away happily for three months in its Azure cloud. You get a sense of the complex and nuanced decisions being made by the model’s minders if you dip into a manual on machine learning, such as this AI wiki for the basics, or these professional tutorials, both from Paperspace. AI engineers are tweaking ‘hyperparameters’, specifying ‘learning batches’ and determining the rate of ‘gradient descent’ towards the model of best fit. I don’t know if they find this a creative process, but I suspect – like all highly specialized design work – it has an aesthetic aspect. The Paperspace dashboard certainly has some lovely visuals.

At least here, among all the layers of labour, is work that is highly valued.
Humans-in-the-loop
After the pre-training stage, the model can produce strings of text that come from the right content areas and resemble the training data ‘norm’ in terms of the ordering of words. But they are often hateful, nonsensical, mistaken, or just unreadable. In human terms they are not fit for use. This is where a different phase of human input starts, and OpenAI is especially coy about what this involves. When you consider that Reinforcement Learning from Human Feedback (RLHF) was one of the developments that enabled the current surge in GenAI, it’s odd that this whole phase is covered by just one sentence in the GPT-4 system release card:
‘Post-training alignment… results in improved performance on measures of factuality and adherence to desired behavior’
This ‘alignment’ to ‘desired behavior’ requires an army of data workers, who are employed through platforms such as Amazon’s Mechanical Turk and Clickworker, more specialized start-up platforms such as ScaleAI, and from cheap labour pools in the global south. Some of the work is traumatic, as revealed by a Time investigation into the development of guardrails for ChatGPT. All of it involves human judgement – identifying, classifying, comparing, accepting, rejecting, rating. With models the size of GPT-4, the process is streamlined somewhat by turning the human feedback into another data set, and using that to build a separate ‘reward’ model, that in turn trains the transformer model towards outputs that humans are more likely to find acceptable.
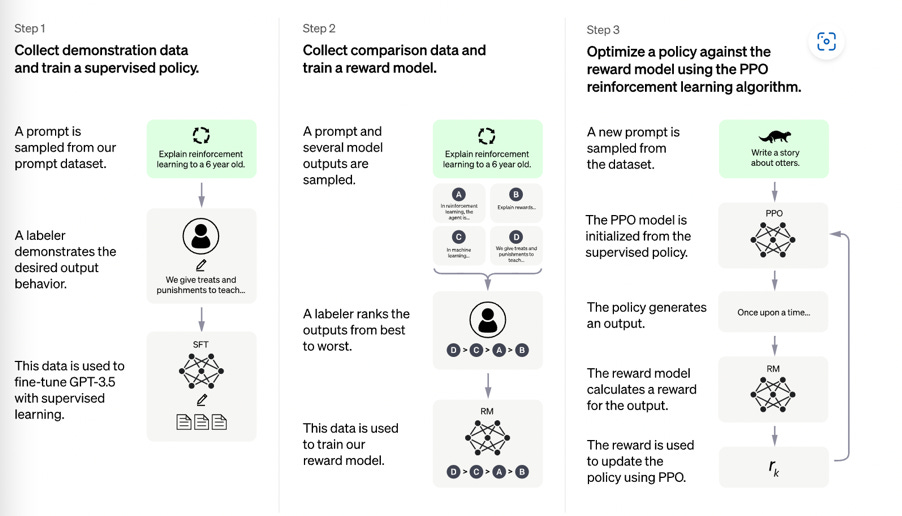
But there is no avoiding the need for extensive human labour. Journalist Josh Dzieza, whose report on working for ScaleAI I found indispensible in writing this piece, reported 100,000 annotators employed on AI projects via just one company. Not surprisingly, shares in data labelling companies have soared in value alongside shares in AI corporations and start-ups.
The terms ‘labeler’ and ‘annotator’ minimize the qualitative aspects of this work. Like the term ‘post-training alignment’ in the technical reports, they make it sound as though the model is ready to fly, and needs just a few last-minute human checks before taking to the air. But here is how Dzieza describes the work involved:
One group of contractors writes examples of how the engineers want the bot to behave, creating questions followed by correct answers, descriptions of computer programs followed by functional code, and requests for tips on committing crimes followed by polite refusals. After the model is trained on these examples, yet more contractors are brought in to prompt it and rank its responses.
This sounds like writing work to me. And some of it is highly skilled. Dzieza speaks to one contractor working on ChatGPT who has:
‘detailed conversations about scientific topics so technical they required extensive research… checking one model’s attempts to code in Python… He couldn’t work for more than four hours at a stretch, lest he risk becoming mentally drained and making mistakes.’
He describes weekly annotation meetings at DeepMind (developers of Sparrow, a rival to ChatGPT) where researchers would ‘rerate data themselves and discuss ambiguous cases, consulting with ethical or subject-matter experts when a case is particularly tricky’.
From a developer perspective, these different kinds of human labour come at different costs. There is no coyness about what is involved on developer-facing sites like HuggingFace:
When deploying a system using RLHF, gathering the human preference data is quite expensive due to the direct integration of other human workers outside the training loop. RLHF performance is only as good as the quality of its human annotations, which takes on two varieties: human-generated text… and labels of human preferences between model outputs. Generating well-written human text answering specific prompts is very costly, as it often requires hiring part-time staff (rather than being able to rely on product users or crowdsourcing).
Dzeiza concurs:
if you want to train a model to do legal research, you need someone with training in law, and this gets expensive. Everyone involved is reluctant to say how much they’re spending, but in general, specialized written examples can go for hundreds of dollars, while expert ratings can cost $50 or more. One engineer told me about buying examples of Socratic dialogues for up to $300 a pop.
Where has the magic gone?
This post is about labour relations and human value, but I have to stop here and wave my arms a bit at the other implications. Inputting dialogue? Writing examples of how the bot should behave? Consulting subject matter experts? Isn’t GPT-4 supposed to produce fully-evolved intelligent behaviour from nothing more than a primordial soup of training text? Using carefully curated examples like this is not unsupervised training. It’s not even reinforcement training. It is supervised training of a fairly traditional kind. It is effective for training a specific use case, such as ‘socratic dialogue’, because the ‘rules’ are fairly easy to extract from an artificial set of examples. What it is not is a flexible, emergent, ‘general’ AI.
There has even been speculation that improvements to ChatGPT outputs could be due to human authoring of answers to the most popular requests. The idea is not that data workers are typing away behind the interface (they would have to be superhuman typists!) but rather that the training process involves purpose-written content, generated to meet user demand. It would certainly be a fast track to improving outputs, whether the content was used to retrain the model or to produce new run-time rules (more about prompt rules in a moment). And improving outputs has been a business imperative since these models were let loose, with all their adolescent problems. I’ve read threads on HackerNews that support the idea of human editing on the fly, and threads that are doubtful, but there is a consensus that anything is possible and none of it is being talked about. OpenAI, Microsoft, Meta and Anthropic have all refused to comment on how many people are contributing to model development (sorry, ‘alignment’) and how. The contribution of different kinds of human labour is at this point incredibly complex and deliberately obscure.
Dzieza again on the wider implications of this:
The model is still a text-prediction machine mimicking patterns in human writing, but now its training corpus has been supplemented with bespoke examples, and the model has been weighted to favor them. Maybe this results in the model extracting patterns from the part of its linguistic map labeled as accurate and producing text that happens to align with the truth, but it can also result in it mimicking the confident style and expert jargon of the accurate text while writing things that are totally wrong.
Enter the audience
I’ll leave the problem of wrongness for another post and get back to the labour issue. Supervised training on paid-for content is very expensive. Examples gathered by scraping data from users, or through crowdsourcing, are far cheaper and can even be better for training because they are closer to real instances of use. (Many of the open source GenAI projects that have sprung up since Meta’s LLAMA model and its weights were leaked back in March make use of crowdsourced and open data sets. Some projects are training models that are small enough to run on a laptop, using records of ChatGPT and OpenChat conversations, much to the annoyance of the two big players who have splashed so much cash down at the data labour exchange.)
At this point in the story, through whatever mix of human labour and model alignment, paid content and cheat-sheets, we are close to a useable version of GPT-4. But there is one more layer of labour before we, the users, can get to work. A set of ‘rules’ is coded into the interface, to run every time a user enters a prompt. These rules may (try to) prevent the model being used in harmful ways; they may (try to) identify and hide offensive content. OpenAI says that it assembled a ‘red team’ of 50 experts to help write these rules for GPT-4. Importantly, stylistic rules are also added, such as the use of the first person voice and other personable characteristics.

Despite it’s coyness here, we do know some of the rules for Bing Chat because a Stanford University student called Kevin Liu revealed them with a prompt exploit and posted them on twitter. The polite refusal to comply with ‘bad’ requests creates an illusion of responsibility. The conversational tics add to the illusion of personality. Once again, the human work of writing the rules is hidden away, in case either illusion is broken.
Education is exploding with start-ups offering bespoke interfaces on the foundational models, or on lightly re-trained copies of them. But every time an educational user sends a prompt to Chat Bing, we are training the foundation model for educational use. Every time we interact with the interface as another person, we are building the dialogic data that keeps the illusion in place.
The magic of making (more) money
What does all this mean for the labour of you, the user, which is where we have finally arrived? As the foundational models become widely used, the demand for data labour may fall away, or at least move elsewhere. Users can now be relied on to discriminate responses they like from responses they don’t, so the AI companies don’t need to pay for labelling. Users are providing a whole range of thoughtful prompts, generating outputs for different use cases and in different domains of expertise. No need for prompt engineers or content writers. To kick start the continuous improvement cycle, all the companies needed was a large user base. And this may be one reason they were keen to rush platforms into use when they were still so full of flaws – a user base is the cheapest way to improve them.
There is nothing in principle wrong with using a body of human knowledge as a resource for generating new insights. Similar mathematical approaches to GenAI have been used for years by scholars in the digital humanities. The community builds and uses the tools and typically shares the outcomes as new knowledge and data. Look sidelong at data labelling and you glimpse something like the semantic web project, in which scholars tagged and labelled web content to make it both machine and human readable, in the belief that the whole web community would benefit from this heroic effort. And Wikipedia, the greatest public knowledge project in human history, is one of the cornerstones of GenAI development. In a different economic order, the labour coordinated by GPT-4 would provide an immense creative commons. True, it would be a typically white, male and anglo-biased one, but this would be something the community could consciously work to improve, as Wikimedia is doing).
We don’t live in that economic order. The function of a platform, by mediating creative work, is to extract value (profit) for the owners of the infrastructure. The platform does not exist to help us learn from each other as producers of text, though sometimes that might happen. It exists to extract value for OpenAI, Microsoft, DeepMind and Google, and to do it ever more efficiently. Microsoft is expected to make $40billion from its initial investment in generative AI. The only workers being paid a living wage in this wide, shallow pyramid of economic intermediation are the AI engineers directly employed by the platform corporations.
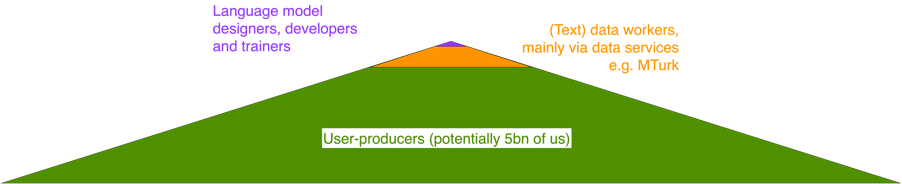
Everyone else is working for nothing, or for the lowest price-per-prompt the labour platform can get away with. And their/our place in this extraction pyramid is fixed. We can’t see how our labour is contributing to a common project. We can’t meet the other workers with whom our labour is being intermixed (what is our relationship with these other writers, exactly?). We can’t aspire to the status of designers, or stakeholders in any but the shallowest sense. In fact, if we are employed in a sector that is embracing GenAI, we are giving our work twice over: once to the platform, and once to our employers, who can extract more productive value from us. A worrying number of search hits on GenAI describe how it can be used to work several full-time jobs at once. As our text work mixes with the text work of others, accelerating the productivity of all, we are all contributing to the devaluation of the work of making text.
Magic is in the eye of the beholder
There is deep irony that Amazon’s Mechanical Turk platform should have contributed so much labour to the early development of GenAI. The original Mechanical Turk, as is well known, was a life-sized automaton that appeared in public from about 1770 to 1885. Its greatest achievement was playing chess against a human opponent, long before ‘Deep Mind’ achieved this feat on a screen. It also conversed in three languages by means of a letter board. In reality, the apparatus hid a human operator who moved the puppet’s hand. The machine was ingenious – a series of magnets allowed the hidden player to follow the course of a game, for example – but it was not ingenious in the way it was claimed to be. It was not what thousands of people paid to see, and persuaded themselves that they were seeing: a mechanical mind. If the truth did not come out until the 1940s it was not only the ingenuity of its design that kept the secret, but the misdirections of the Turk’s promotors, and the desire of the paying public to believe this outrageous proposition.

(Of course the Turk was also a racial stereotype, though one based on the real history of Arabs bringing chess to Europe, and being admired for their mathematical thought. It is interesting to speculate how far the ‘otherness’ of the Turk’s persona helped to sustain confusion about what kind of ‘other’ mind was at work.)
GenAI is more than a clever box, but the human work it coordinates in layer after hidden layer is not credited, any more than the hidden chess players were credited (though Wikipedia now names them all). Human writing and human judgement about writing are missing from the technical record, or swallowed in phrases like ‘post-training alignment’. Human beings hide in the acronym ‘RLHF’. Mary L Gray and Siddarth Suri in Ghost Work, and Virginia Eubanks in Automating Inequality (the link is to an excellent review) have described what it is like to labour under platform capitalism in situations of real deprivation. Dzieza’s experience of labouring ‘alongside’ AI was relatively privileged. It was the kind of experience we might be preparing our own students for, if we accept that only a tiny minority will make it to the top of the pyramid. But it is still exploitation. It is still sucking up the work of creative millions into the data centres and swilling it round and spitting it out again, whether that’s good for our collective writing culture or not. All so that a handful of people can profit.
Apart from the insecurity and unpredictable pay, Dzieza found data work difficult and mentally disorientating:
The act of simplifying reality for a machine results in a great deal of complexity for the human.
I can’t help thinking of all the advice that teachers are being given, about how to craft and re-craft complex prompts for GenAI. Because that’s your job now, to engineer your own words to make the GenAI ‘work’. At least the data workers are being paid something for bending their minds to the shape of the machine. I just wonder what we are getting out of it. Surely it’s more than the thrill of the trick, the wonder of being alive in the year that an AI takes to the stage? Is it really so compelling to have human words spilling out of a machine that we will keep feeding it with our own words and our students’ words, just so we can say that we we were there?
This is spectacular - thank you Helen!